

Last updated on November 12, 2020
By Shivani Patel
What is BERT’s connection to NLP?
In a previous post, we discussed Natural Language Processing and highlighted a couple of its applications. Natural Language Processing, or rather NLP for short, is the study of how linguistics, speech, and text can be interpreted and manipulated by computers [1]. Common applications of NLP include language translation, grammar checker systems, and personal assistants such as Siri or Alexa [2]. These specific tasks, better known as downstream tasks, are implemented through the use of natural language models such as BERT. Created by Google, BERT (Bidirectional Encoder Representations from Transformers) generates a language model by learning the related context between words or phrases in a text
How does BERT Work?
Language models use statistical analysis to determine the probability that a word will be followed by another word by going through a series of trial/error predictions on a large corpus of text. BERT is designed to “learn” a language by making predictions by first putting all of the text into word phrases, such as ‘SD card’ or ‘The United States.’ Afterwards, BERT analyses the probability that a word phrase will be followed by another word phrase by using the context to the right and to the left of the word phrase [3]. Typically, language models before BERT, such as ELMo, did not look at both context to the left and right (bidirectional) because they only formed predictions from what was to the left of the word [3] . BERT is implemented through two steps: pre-training and fine-tuning [3]
Pre-Training
Masked LM
Each word phrase is denoted as a token, and some of the tokens are randomly “masked” from the language model so that it is hidden [3], [4]. In the pre-training, the language model’s goal is to predict the masked tokens based on its surrounding context [3]. The pre-training methodology relies on using the context from both directions, right-to-left and left-to-right to the masked token. In BERT’s pre-training procedure, BERT primarily uses data from BooksCorpus and English Wikipedia (only text passages) because their corpus contains adjoining sequences of text [3]. This is important because it allows the language model to understand how sentences and words should be connected with one another. If the corpus was trained on a series of shuffled sequences of tokens, it would not be able to accurately predict words or sentences that should follow.
Next Sentence Prediction
Afterward, BERT performs its training procedure upon pairs of sentences rather than its tokens (phrases) as many downstream tasks require LMs (language models) to understand the connection between two different sentences [3], [4]. For example, if the downstream task is matching questions along with their appropriate answer, the next sentence prediction would allow the model to yield better results. BERT accomplishes this by choosing two sentences, sentence A and sentence B, such that sentence B has a 50% chance of preceding sentence A in the corpus [3], [4]. This training is significant because the BERT model requires an accurate reference for question-answering or natural language inference tasks [3].
Fine-Tuning
Fine-tuning is rather inexpensive and relatively straightforward compared to the pre-training [3]. The tasks completed in BERT’s pre-training (Masked LM and Next Sentence Prediction) permits BERT to be a model for different downstream tasks such as classification or question-answering [4]. To fine-tune the BERT model to a specific task, most of the parameters of the model set are kept the same as from the pre-training, but parameters such as batch size and learning rate need to be re-adjusted [3]. Because fine-tuning is relatively inexpensive in terms of space and time, the algorithm runs an exhaustive search over these parameters to find the optimal set of parameters [3], [5].
How effective is BERT?
Proven by various analyses, BERT outperforms its competitors through its bidirectional design and robust capabilities. [6] With its simple concept yet powerful design, BERT pushes the previously known best results on LMs in eleven different NLP tasks [3]. Furthermore, it can be fine-tuned to train in a specific genre of text by slight manipulations [7], [8]. Because of BERT’s ability to ‘read’ broad language and its capability to fine-tune to specific required tasks, BERT is an all-embracing tool in Natural Language Processing [6].
Different Variations of BERT
Since the release of BERT, several other language models have spawned from it by either utilizing its design concept or fine-tuning BERT to specific tasks [7].
SciBERT
SciBERT was created specifically based on BERT’s inability to address scientific data with precision and high quality [7]. The process to develop SciBERT differed from the method used to create BERT because the corpus (collection of text passages) used was different. BERT is originally trained using text from Wikipedia and BooksCorpus, whereas SciBERT trained by using random computer science and biomedical samples from Semantic Scholar [3], [7]. SciBERT utilized the original BERT code and configurations on its scientific corpus during its pre-training tasks. Similarly, SciBERT followed the same strategy as BERT to fine-tune its parameters by an exhaustive search. The exhaustive search goes through every set of parameters and picks the model that had the best performance [sm5] [7]. Overall, SciBERT excels in computer science tasks and biomedical tasks compared to BERT’s base model because the original corpus contains scientific data. This language model can evaluate various downstream tasks such as sentence classification and sequence tagging on datasets from scientific domains [7].
M-BERT
Because BERT’s training corpus was solely using English data with an English-derived vocabulary, Multilingual BERT, abbreviated to M-BERT, rectifies BERT’s inefficiency to sort through data in multiple languages [3], [8]. M-BERT forms a single, multilingual vocabulary by making its corpus inclusive of different languages by training on Wikipedia pages of 104 languages such as Hebrew, Swedish, and Chinese [8]. Like BERT’s methodology, M-BERT tokenizes the corpus into tokens and passes it through the language model to pre-train. Afterward, the model is fine-tuned to maximize its precision for downstream tasks. This LM performs well in different languages, and surprisingly, it has a strong ability to generalize cross-lingually even though it was not explicitly trained for it [8].
Transferable BERT
Story ending prediction, also known as Story Cloze Test, is one of the downstream tasks that BERT could handle, but it is not optimized to give the best results[3], [9]. Story Cloze Test is a task that evaluates story comprehension by determining the appropriate ending given two candidates [9]. In the figure below, there is an example of a story ending prediction of how the LM must decide which ending should be correct given two candidates [9]. Though BERT’s LM trains using a Next Sentence Predictor, it does not transfer learned information from the previous sentence(s) in the input text [3], [9]. To clarify, BERT would not consider “It was my final performance … played Thriller and Radar Love” in conjunction with “The performance was flawless.” when predicting which candidate is better. TransBERT provides better results when performing story ending prediction tasks through its unique three-stage training framework: unsupervised pre-training, supervised pre-training, and supervised fine-tuning [9].
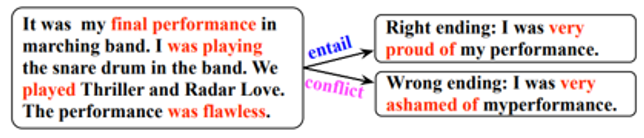
The unsupervised pre-training follows the procedure outlined by BERT of using masked language modeling and next sentence prediction to allow the model to understand general relations between the language [3], [9]. Given the output from the unsupervised pre-training, the parameters are now set to what will achieve the most accurate model for the target task through an exhaustive search [9]. After the pre-training stages, the model is fine-tuned to solve story cloze tests by adjusting the task-specific parameters [9].
TransBERT allows for specific downstream tasks that require particular kinds of knowledge from supervised tasks such as story ending prediction to have better accuracy and performance [9].
VideoBERT
VideoBERT utilizes self-supervised learning and outperforms the state-of-the-art language model on video captioning, Zhou et al [10]. VideoBERT combs through both visual content and words spoken in the video [10]. Through this conjunction of input, the model can perform a variety of tasks easily [10]. The LM turns the visual footage into a sequence of tokens (known as “visual words”) and then inputs it into BERT’s original pre-training tasks [10]. VideoBERT extracted videos from YouTube and removed all videos longer than 15 minutes, which resulted in a dataset of 312K videos, to form its corpus [10]. Before VideoBERT, the dataset used to train the Zhou et al only had approximately 2K videos (YouCook II dataset); in fact, YouCook II was used to evaluate the efficiency of VideoBERT [10]. VideoBERT can be directly used for video captioning, video prediction, open-vocabulary classification, and action classification because it learns high-level semantic features [10].

Limitations of BERT
Because of its various applications on downstream tasks and its ability to be turned into more task-specific models, BERT is one of the most robust language models with exceptionally great performance [3]. However, BERT shows insensitivity when understanding negation [3], [11]. To understand this in a simple context, review the sentences below:
A robin is a ________ Predictions: bird, robin, person, hunter, pigeon
A robin is not a _____ Predictions: robin, bird, penguin, man, fly [11]
If a robin is predicted to be a bird, how could a robin be predicted not to be a bird? In tests like the one above, its accuracy can be evaluated by truth judgment [11]. As you can note from the example, BERT failed to adjust for the negation of a statement which showcases that BERT contradicts its own predictions [11].
Furthermore, BERT struggles to understand role-based event prediction, such as a prediction composed of two connected sentences. For example, “He caught the pass and scored another touchdown. There was nothing he enjoyed more than a good game of ____” returns baseball and monopoly as the prediction when it should be football. Though models such as TransBERT rectify this issue, it is only specific to the story ending prediction tasks of deciding between which conclusion statement is more appropriate [9]. When BERT is used to predict the last word of a series of sentences, it failed to utilize the prior sentences as connections and coreferences [9].
The results of BERT are compared to other language models that utilize a unidirectional methodology (from left-to-right). It would be unjust to compare a model that uses a bidirectional methodology with a unidirectional methodology. This issue is rectified by purposely making BERT predict the last word in the test cases, so that it acts similar to a unidirectional methodology [11]. Through analysis of these various case studies, it has been proven that BERT has weaknesses that may be disregarded because of its innovative ability to decipher text through bidirectional training and fine-tuning capabilities [3], [11]. Despite these limitations, BERT has made a tremendous impact in Natural Language Processing because of its ability to be transformed into a language model for a NLP particular task.
Works Citied
[1] “What Is Natural Language Processing?” https://machinelearningmastery.com/natural-language-processing/ (accessed Oct. 27, 2020).
[2] “A Simple Introduction to Natural Language Processing | by Dr. Michael J. Garbade | Becoming Human: Artificial Intelligence Magazine.” https://becominghuman.ai/a-simple-introduction-to-natural-language-processing-ea66a1747b32 (accessed Oct. 27, 2020).
[3] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” ArXiv181004805 Cs, May 2019, Accessed: Oct. 25, 2020. [Online]. Available: http://arxiv.org/abs/1810.04805.
[4] “BERT Explained: State of the art language model for NLP | by Rani Horev | Towards Data Science.” https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270 (accessed Oct. 27, 2020).
[5] “Painless Fine-Tuning of BERT in Pytorch | by Kabir Ahuja | The Startup | Medium.” https://medium.com/swlh/painless-fine-tuning-of-bert-in-pytorch-b91c14912caa (accessed Nov. 12, 2020).
[6] “Pre-trained Language Models: Simplified | by Prakhar Ganesh | Towards Data Science.” https://towardsdatascience.com/pre-trained-language-models-simplified-b8ec80c62217 (accessed Oct. 28, 2020).
[7] I. Beltagy, K. Lo, and A. Cohan, “SciBERT: A Pretrained Language Model for Scientific Text,” ArXiv190310676 Cs, Sep. 2019, Accessed: Oct. 26, 2020. [Online]. Available: http://arxiv.org/abs/1903.10676.
[8] T. Pires, E. Schlinger, and D. Garrette, “How multilingual is Multilingual BERT?,” ArXiv190601502 Cs, Jun. 2019, Accessed: Oct. 26, 2020. [Online]. Available: http://arxiv.org/abs/1906.01502.
[9] Z. Li, X. Ding, and T. Liu, “Story Ending Prediction by Transferable BERT,” ArXiv190507504 Cs, May 2019, Accessed: Oct. 26, 2020. [Online]. Available: http://arxiv.org/abs/1905.07504.
[10] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “VideoBERT: A Joint Model for Video and Language Representation Learning,” ArXiv190401766 Cs, Sep. 2019, Accessed: Oct. 25, 2020. [Online]. Available: http://arxiv.org/abs/1904.01766.
[11] A. Ettinger, “What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models,” Trans. Assoc. Comput. Linguist., vol. 8, pp. 34–48, Jul. 2020, doi: 10.1162/tacl_a_00298.
Featured Image Provided by Medium.
